

If you are a Network Engineer working for an Enterprise, you may not work with BGP as often as someone at an ISP does. In most cases, you will only run BGP at the edge of your network to peer with your ISP and leave it at that. There are many ways to connect to an ISP. If you are a small company without your own IP address space or autonomous system, you typically rely on the ISP to allocate a portion of their IP space for you, and you use a static route pointing to them (single-homed). For redundancy, you might connect to two ISPs or take two diverse links from the same ISP (dual-homed/multi-homed). In many of those setups, you may not run BGP yourself, but it depends on the design.
In this post, we will look at a scenario where you already have your own IP address space and an AS number, and you connect to two different ISPs. You will advertise your IP space to the Internet via both ISPs and, at the same time, receive the full Internet routing table from both ISPs.
If you are completely new to BGP, I recommend checking out the previous posts linked below, where we covered topics like BGP introduction, eBGP, iBGP, path attributes, and more.

As always, if you find this post helpful, press the ‘clap’ button. It means a lot to me and helps me know you enjoy this type of content. If I get enough claps for this series, I’ll make sure to write more on this specific topic.
Overview and Diagram
When we refer to BGP multi-homing, it means the enterprise network is connected to two separate ISPs using two different edge routers. Each router peers with one ISP and exchanges routes using eBGP. This setup gives you redundancy and better availability since your network can still reach the Internet even if one ISP or one router fails.
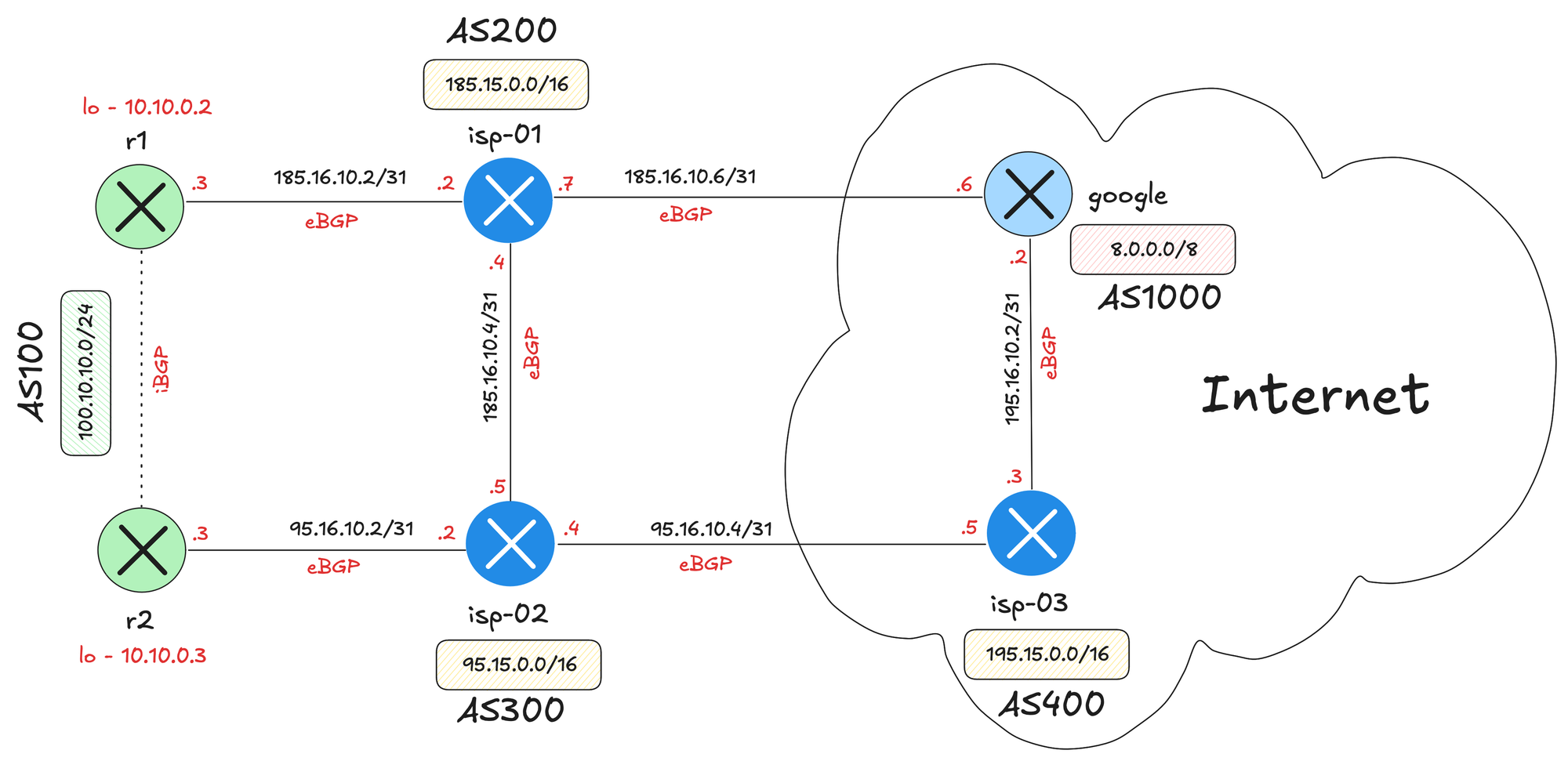
Throughout this post, we will be using the diagram above.
- We, the enterprise customer, have two routers, r1 and r2
- We advertise our own prefix
100.10.10.0/24to both ISP-01 and ISP-02 - Our AS number is 100
- iBGP between r1 and r2
- We advertise our own prefix
- isp-01 is in AS200 and has its own prefix
185.15.0.0/16 - isp-02 is in AS300 and has its own prefix
95.15.0.0/16 - isp-03 is in AS400 with prefix
195.15.0.0/16 - Google is in AS1000 with prefix
8.0.0.0/8
We can think of isp-03 and Google as the wider Internet. At the same time, isp-01 and isp-02 are also part of the Internet since they have their own prefixes that could be allocated to different customers. We will eventually need to reach services using those addresses as well.
For now, we will focus only on the eBGP sessions between our routers and the two ISPs, along with iBGP between r1 and r2. isp-01 and isp-02 also run eBGP between them in this example, but that part is outside of our control, and we do not need to know the details.
Lab Guide
If you would like to follow along and build this lab yourself, I am using Netlab to spin up the entire lab. With Netlab, all you need is a single YAML file (attached below) along with the Cisco image, and the full topology can be created automatically, including the configuration.
I have already covered Netlab and Containerlab in detail in the post linked below, so I won’t repeat that here. I will also attach the YAML file for this lab so you can easily recreate the exact same environment.


BGP Configuration
On both r1 and r2, everything is kept at the default. Each router has one iBGP session to the other router and one eBGP session to its respective ISP. You will often notice that BGP configuration is placed under an address-family section. Address families in BGP simply define what type of routes we want to exchange.
In some versions of BGP configuration, you would see neighbours defined directly under the main BGP process. In modern configurations, you usually see the neighbours defined under the global section but activated inside the specific address family. This makes it clear what type of routes the neighbour will exchange and allows you to use the same BGP session for multiple address families if needed.
!! r1 !!
router bgp 100
bgp router-id 10.0.0.2
no bgp default ipv4-unicast
neighbor 10.0.0.3 remote-as 100
neighbor 10.0.0.3 description r2
neighbor 10.0.0.3 update-source Loopback0
neighbor 185.16.10.2 remote-as 200
neighbor 185.16.10.2 description isp-01
!
address-family ipv4
network 100.10.10.0 mask 255.255.255.0
neighbor 10.0.0.3 activate
neighbor 10.0.0.3 next-hop-self
neighbor 185.16.10.2 activate!! r2 !!
router bgp 100
bgp router-id 10.0.0.3
no bgp default ipv4-unicast
neighbor 10.0.0.2 remote-as 100
neighbor 10.0.0.2 description r1
neighbor 10.0.0.2 update-source Loopback0
neighbor 95.16.10.2 remote-as 300
neighbor 95.16.10.2 description isp-02
!
address-family ipv4
network 100.10.10.0 mask 255.255.255.0
neighbor 10.0.0.2 activate
neighbor 10.0.0.2 next-hop-self
neighbor 95.16.10.2 activate
neighbor 95.16.10.2 advertisement-interval 0iBGP Between the Routers
We need iBGP between our two routers so that each router can learn the routes received by the other. This allows them to make better decisions about which router has the preferred path to reach a destination on the Internet.
Without iBGP, the routers would have no way of knowing what routes the other router has learned from its ISP. That means each router would only know about the prefixes it received directly from its own ISP and would not be able to forward traffic to the other router if that path happened to be better.
update-source
For the iBGP session, we are using the loopback IPs for BGP peering, so we need to use the update-source Loopback0 command. Since the peering is established with loopbacks (r1 uses 10.0.0.2 and r2 uses 10.0.0.3), each router must know how to reach the other’s loopback. To make this work, we are running OSPF between r1 and r2. Strictly speaking, this is not required. If you don’t want to bother with OSPF or another IGP, you can simply peer using the directly connected interface IPs.
next-hop-self
We will also use the next-hop-self command for iBGP peers. By default, when a router receives a route from an eBGP neighbour and advertises it to an iBGP peer, it does not change the next-hop attribute. This means the eBGP peer would see the original next-hop, which would be the ISP router, and might not have a way to reach it. The next-hop-self command tells the router to set itself as the next-hop when advertising routes to its iBGP peers. This ensures that each router forwards traffic to its iBGP peer correctly without trying to reach the ISP’s next-hop directly, which may not be reachable within the enterprise network.
If you don’t want to use next-hop-self, then you need to make sure each router knows how to reach the external ISP-facing IP from the other side. One way to do this is by injecting those external interface IPs into OSPF. For example, r1 would need to learn how to reach isp-02’s IP address, and r2 would need to know how to reach isp-01’s IP address. This way, the original next-hop values are preserved within the iBGP updates.
Route Propagation
Both r1 and r2 advertise our enterprise prefix 100.10.10.0/24 to their respective ISPs. r1 advertises it to isp-01, and r2 advertises it to isp-02. Each ISP then advertises the prefix further to their peers, to each other and upstream providers, depending on their own BGP policy. For example, isp-01 will advertise 100.10.10.0/24 to Google and to any other peers it may have. isp-02 will do the same with its own peers and with isp-03.
As a result, Google (AS1000) will eventually learn about our prefix through both isp-01 and isp-03 (via isp-02). When Google receives multiple paths to the same prefix, it uses the BGP best path selection process to choose which route to prefer. If all attributes are equal, the path through isp-01 will be selected, since it has a shorter AS path compared to the one learned through isp-02 and isp-03.
Now, let’s look at it in the other direction with Google’s prefix 8.0.0.0/8. Google advertises this prefix to its peers, such as isp-03 and isp-01. isp-03 then advertises 8.0.0.0/8 to isp-02. From there, isp-01 and isp-02 advertise it to r1 and r2. Because we are running iBGP between r1 and r2, both routers will also advertise the prefix to each other.
Please note that BGP peers only advertise their best route to their neighbours, not all available routes. For example, isp-02 may learn about the prefix 8.0.0.0/8 from both isp-01 and isp-03, but it will select the best path based on its own policies and then advertise only that single best path to r2. BGP also has a built-in loop prevention mechanism. If an eBGP speaker receives a route where its own AS number is already present in the AS path, it will discard that route. This ensures that routing loops cannot form between autonomous systems.
For example, if isp-02 decides that the prefix it received from isp-01 is the best path, it may re-advertise that path back to isp-01. However, isp-01 will immediately discard it because it sees its own AS number already in the AS path.
Path to Reach Google
If we look at the route tables from both r1 and r2, we notice something interesting. On r1, the route to 8.0.0.0/8 comes directly from isp-01. The next-hop is 185.16.10.2, which belongs to isp-01.

On r2, things look a bit different. r2 receives the prefix 8.0.0.0/8 from isp-02. Now, isp-02 itself learns this prefix from both isp-01 and isp-03 directly. Based on its own BGP policies, isp-02 chooses the path via isp-01 as the best and then advertises that best path to r2. At the same time, r2 also learns about 8.0.0.0/8 from r1 over iBGP. From r2’s perspective, it now has two paths to reach the prefix.
- One from r1, with the AS path 1000 200
- One from isp-02, with the AS path 1000 200 300
* next to a prefix in the BGP table, it means the route is valid. If you see a >, it means that route has been selected as the best path and is installed in the routing table.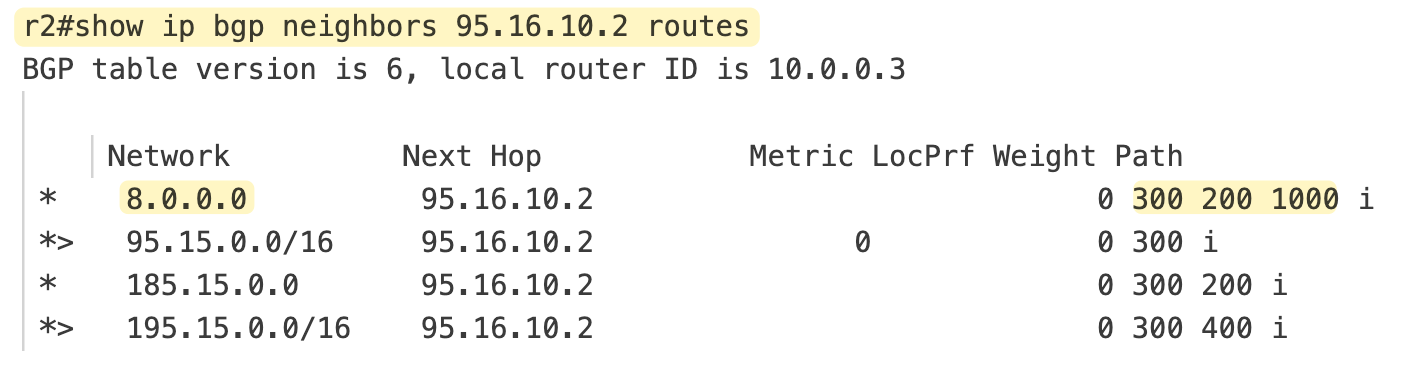

Since BGP prefers the shortest AS path when other attributes are equal, r2 installs the path via r1 as the best route. That is why r2’s routing table shows the next-hop as r1 (10.0.0.2) instead of its own isp-02.
On top of 8.0.0.0/8, you can also see routes for other prefixes, and they follow the same mechanism. For example, if we look at the prefix 95.15.0.0/16, which belongs to isp-02, r2 has the best path via isp-02 since it is directly connected. r1 also prefers to reach this prefix through r2, because that path has the shortest AS path compared to going through isp-01 > isp-02.
So far, things look fine, but there is a major problem here that we need to look at next.
Prevent Transit Routing
One important thing we need to take care of in a multi-homed BGP setup is preventing transit routing. Transit routing happens when traffic from other autonomous systems comes into our network and then leaves to reach a different autonomous system. If we are an Enterprise, we absolutely don't want this.

Without proper filtering, if r1 receives the full Internet table from isp-01 and then advertises those routes to isp-02 (via r2), it is essentially telling isp-02, “You can reach all these Internet prefixes through me.” That would make our network a transit path between ISPs and other ASes, which is exactly what we want to avoid.
Typically, ISPs already do their due diligence by applying policies on their side. They usually only accept customer-originated prefixes (in our case, 100.10.10.0/24) and reject anything else. But from our side, we also need to be careful. We should make sure we only advertise our own prefixes to the ISPs and never pass along the routes we learn from one ISP to another.
If we look at r1 and check what it advertises to isp-01, we can see it is not only sending our own prefix, but it is also sending prefixes learned from r2. That is a problem. We only want to advertise 100.10.10.0/24 to the ISP and nothing else.
r1#show ip bgp neighbors 185.16.10.2 advertised-routes
BGP table version is 8, local router ID is 10.0.0.2
Network Next Hop Metric LocPrf Weight Path
*>i 95.15.0.0/16 10.0.0.3 0 100 0 300 i
*> 100.10.10.0/24 0.0.0.0 0 32768 i
*>i 195.15.0.0/16 10.0.0.3 0 100 0 300 400 i
Total number of prefixes 3 r2#show ip bgp neighbors 95.16.10.2 advertised-routes
BGP table version is 6, local router ID is 10.0.0.3
Network Next Hop Metric LocPrf Weight Path
*>i 8.0.0.0 10.0.0.2 0 100 0 200 1000 i
*> 100.10.10.0/24 0.0.0.0 0 32768 i
*>i 185.15.0.0 10.0.0.2 0 100 0 200 i
Total number of prefixes 3Using IP Prefix-List
To fix this, we set up outbound filtering. The usual approach is.
- Create a prefix list that matches only our prefix.
- Create a route map that permits the prefixes matched by that list and denies everything else (route-map has an implicit deny)
- Apply that route map to the BGP neighbour in the outbound direction.
!! r1 !!
ip prefix-list MY-PREFIX seq 5 permit 100.10.10.0/24
!
route-map ALLOW-MY-PREFIX permit 10
match ip address prefix-list MY-PREFIX
!
router bgp 100
address-family ipv4
neighbor 185.16.10.2 route-map ALLOW-MY-PREFIX out
!! r2 !!
ip prefix-list MY-PREFIX seq 5 permit 100.10.10.0/24
!
route-map ALLOW-MY-PREFIX permit 10
match ip address prefix-list MY-PREFIX
!
router bgp 100
address-family ipv4
neighbor 95.16.10.2 route-map ALLOW-MY-PREFIX outWith this in place, r1 will advertise only our prefix to isp-01, and r2 will do the same toward isp-02. This stops us from becoming a transit path for other ASes.
r1#show ip bgp neighbors 185.16.10.2 advertised-routes
BGP table version is 8, local router ID is 10.0.0.2
Network Next Hop Metric LocPrf Weight Path
*> 100.10.10.0/24 0.0.0.0 0 32768 i
Total number of prefixes 1r2#show ip bgp neighbors 95.16.10.2 advertised-routes
BGP table version is 6, local router ID is 10.0.0.3
Network Next Hop Metric LocPrf Weight Path
*> 100.10.10.0/24 0.0.0.0 0 32768 iUsing AS Path Filter
In the previous example, we saw that we can use a prefix list to make sure we only advertise our own prefixes. Another way to achieve the same result is by using AS path filtering.
With AS path filtering, we can specify that we only want to advertise routes that we originate ourselves. When we originate a prefix, the AS path is empty (other than the origin code i), since the prefix hasn’t passed through any other autonomous systems yet.
To match this, we can use the regular expression ^$. In regex, ^ means "start of the string" and $ means "end of the string". Together, ^$ matches an empty string, which in BGP terms means the AS path is empty. That effectively filters for only our locally originated prefixes.
!! r1 !!
ip as-path access-list 1 permit ^$
!
route-map AS_PATH_FILTER permit 10
match as-path 1
!
router bgp 100
address-family ipv4
neighbor 185.16.10.2 route-map AS_PATH_FILTER out!! r2 !!
ip as-path access-list 1 permit ^$
!
route-map AS_PATH_FILTER permit 10
match as-path 1
!
router bgp 100
address-family ipv4
neighbor 95.16.10.2 route-map AS_PATH_FILTER outWith this applied, r1 and r2 will only advertise prefixes that it originates (like 100.10.10.0/24) to isp-01.
Using Local Preference to Prefer Outbound Path
There might be scenarios where we want to prefer one ISP over the other for all outbound traffic. Here is the output from r2 as of now, where we can see it uses isp-02 for some prefixes (denoted via 95.16.10.2)
r2#show ip route bgp
B 8.0.0.0/8 [200/0] via 10.0.0.2, 1d20h
95.0.0.0/8 is variably subnetted, 3 subnets, 3 masks
B 95.15.0.0/16 [20/0] via 95.16.10.2, 1d20h
B 185.15.0.0/16 [200/0] via 10.0.0.2, 1d20h
B 195.15.0.0/16 [20/0] via 95.16.10.2, 1d20hHowever, if isp-01 provides higher bandwidth compared to isp-02, we may want to send all our Internet traffic through isp-01 and only use isp-02 as a backup. We can do this using the local preference attribute. By default, local preference is set to 100. If we apply a higher local preference (say 110) to all the routes we receive from isp-01, those routes will be more preferred inside our AS. Because r1 will advertise these routes with the higher local preference to r2, r2 will see two options.
- The prefix received from r1 (via isp-01) with local preference 110
- The same prefix received directly from isp-02 with the default local preference 100
Since BGP prefers the path with the highest local preference, r2 will choose the path through r1 and then out via isp-01. To configure this, we create a route map that matches all prefixes (no prefix list is required since we want to apply it to everything) and then set the local preference to 110. This route map is applied to the neighbour statement for isp-01 in the inbound direction, so that all routes coming from isp-01 get the higher preference.
!! r1 !!
route-map LOCAL-PREF-110 permit 10
set local-preference 110
!
router bgp 100
address-family ipv4
neighbor 185.16.10.2 route-map LOCAL-PREF-110 inIf we now check the route table on r2, we can see that it points to r1 for all Internet traffic. (Denoted via 10.0.0.2)
r2#show ip route bgp
B 8.0.0.0/8 [200/0] via 10.0.0.2, 00:00:48
95.0.0.0/8 is variably subnetted, 3 subnets, 3 masks
B 95.15.0.0/16 [200/0] via 10.0.0.2, 00:00:48
B 185.15.0.0/16 [200/0] via 10.0.0.2, 00:00:48
B 195.15.0.0/16 [200/0] via 10.0.0.2, 00:00:48We also see that all prefixes received from r1 have a local preference of 110, which makes them more preferred than the same prefixes learned directly from isp-02 with the default value of 100. This confirms that our local preference policy is working as expected.
r2#show ip bgp neighbors 10.0.0.2 routes
BGP table version is 10, local router ID is 10.0.0.3
Network Next Hop Metric LocPrf Weight Path
*>i 8.0.0.0 10.0.0.2 0 110 0 200 1000 i
*>i 95.15.0.0/16 10.0.0.2 0 110 0 200 300 i
* i 100.10.10.0/24 10.0.0.2 0 100 0 i
*>i 185.15.0.0 10.0.0.2 0 110 0 200 i
*>i 195.15.0.0/16 10.0.0.2 0 110 0 200 1000 400 i
Total number of prefixes 5Influencing Inbound Path via AS Path Prepend
So far, we have controlled our outbound traffic using local preference. But sometimes we also want to influence the inbound traffic, meaning how the rest of the Internet chooses to reach us. One common way to do this is AS path prepending. With AS path prepend, we artificially make a route advertisement look longer by repeating our own AS number multiple times before sending it to a specific ISP.
For example, let’s say we want most of the Internet to reach us through isp-01. To make that happen, we can prepend our AS 100 several times when advertising our prefix to isp-02. This way, from the perspective of other autonomous systems, the path to reach us through isp-02 looks longer than the path through isp-01. As a result, the majority of inbound traffic will prefer isp-01, while isp-02 remains available as a backup path.
Please remember we already have a route map applied in the outbound direction to isp-02 on r2, so we don’t need to create a new one. We just need to update the existing one, as shown below.
!! r2 !!
route-map ALLOW-MY-PREFIX permit 10
match ip address prefix-list MY-PREFIX
set as-path prepend 100 100
OR (if you used AS path filter)
route-map AS_PATH_FILTER permit 10
match as-path 1
set as-path prepend 100 100Once this change is in place, if you log in to the isp-02 router, you should see that the AS path prepending is working. From isp-02’s perspective, the path to reach 100.10.10.0/24 will now look longer, and the best path to reach that prefix will be via isp-01.
isp-02#show ip bgp neighbors 95.16.10.3 routes
BGP table version is 10, local router ID is 10.0.0.6
Network Next Hop Metric LocPrf Weight Path
* 100.10.10.0/24 95.16.10.3 0 0 100 100 100 iisp-02#show ip route bgp
B 8.0.0.0/8 [20/0] via 185.16.10.4, 1d20h
100.0.0.0/24 is subnetted, 1 subnets
B 100.10.10.0 [20/0] via 185.16.10.4, 00:07:38 <<< via isp-01
B 185.15.0.0/16 [20/0] via 185.16.10.4, 1d20h
B 195.15.0.0/16 [20/0] via 95.16.10.5, 1d20hOriginating BGP Default Route from the ISP
Sometimes it is not a good idea to receive the entire Internet routing table from the ISP. Instead, we may only want to receive a single default route and be done with it. This approach is useful if we already know we want to prefer one ISP for all outbound and inbound traffic. In that case, we don’t really care about having the absolute best path to each individual prefix on the Internet.
To achieve this, you can ask both ISPs to advertise the default route (0.0.0.0/0) to your routers. On the ISP side, this is done by using the default-originate command under the BGP neighbor configuration. This way, your routers learn the default route from the ISPs and send all Internet-bound traffic toward them, without having to process or store the full Internet table.
!! isp-01 !!
router bgp 200
address-family ipv4
neighbor 185.16.10.3 default-originate!! isp-02 !!
!! isp-01 !!
router bgp 300
address-family ipv4
neighbor 95.16.10.3 default-originatedefault-originate to work. This command also bypasses any outbound route filters configured on the originating router.As of now, even though we are receiving the default route from the ISP, we are still also receiving other prefixes, such as 8.0.0.0/8 and the ISP’s own prefixes like 185.15.0.0/16.
r1#show ip route bgp
B* 0.0.0.0/0 [20/0] via 185.16.10.2, 00:00:14
B 8.0.0.0/8 [20/0] via 185.16.10.2, 17:27:19
95.0.0.0/16 is subnetted, 1 subnets
B 95.15.0.0 [20/0] via 185.16.10.2, 17:27:19
B 185.15.0.0/16 [20/0] via 185.16.10.2, 17:27:19
B 195.15.0.0/16 [20/0] via 185.16.10.2, 17:27:19So next, let’s look at how to make sure we only receive the default route from both ISPs along with their own originating prefixes, and nothing else. We can handle this in two ways. Either we control it on our side by filtering inbound routes, or we ask the ISP to apply the filter on their side.

BGP Filtering Inbound
The configuration for this is similar to what we covered earlier. We create prefix lists that match the default route and the respective ISP’s own prefixes, then build a route map to match those lists and apply it to the BGP peer in the inbound direction.
!! r1 !!
ip prefix-list DEFAULT_PREFIX seq 10 permit 0.0.0.0/0
!
ip prefix-list ISP01-PREFIX seq 10 permit 185.15.0.0/16
!
route-map INBOUND_MAP permit 10
match ip address prefix-list DEFAULT_PREFIX
set local-preference 110
!
route-map INBOUND_MAP permit 20
match ip address prefix-list ISP01-PREFIX
!
router bgp 100
address-family ipv4
neighbor 185.16.10.2 route-map INBOUND_MAP in!! r2 !!
ip prefix-list DEFAULT_PREFIX seq 10 permit 0.0.0.0/0
!
ip prefix-list ISP02-PREFIX seq 10 permit 95.15.0.0/16
!
route-map INBOUND_MAP permit 10
match ip address prefix-list DEFAULT_PREFIX
!
route-map INBOUND_MAP permit 20
match ip address prefix-list ISP02-PREFIX
!
router bgp 100
address-family ipv4
neighbor 95.16.10.2 route-map INBOUND_MAP inI am creating two separate prefix lists on r1 because I still want to apply a higher local preference to the default route received from isp-01, but not to the ISP’s own prefixes. This way, if r1 needs to access 95.16.0.0/16, it can send the traffic directly to isp-02 instead of routing it unnecessarily through isp-01.
r1#show ip route bgp
B* 0.0.0.0/0 [20/0] via 185.16.10.2, 00:33:13
95.0.0.0/16 is subnetted, 1 subnets
B 95.15.0.0 [200/0] via 10.0.0.3, 00:08:15
B 185.15.0.0/16 [20/0] via 185.16.10.2, 00:08:15r2#show ip route bgp
B* 0.0.0.0/0 [200/0] via 10.0.0.2, 00:00:55
95.0.0.0/8 is variably subnetted, 3 subnets, 3 masks
B 95.15.0.0/16 [20/0] via 95.16.10.2, 00:08:22
B 185.15.0.0/16 [200/0] via 10.0.0.2, 00:08:22As you can see, the default route received from isp-01 has a higher local preference. This means that from r2’s perspective, the best path to reach the Internet is via r1 and then out through isp-01.
However, when it comes to reaching isp-02’s own prefix, r1 prefers the path via r2 and then directly to isp-02. This ensures that we don’t end up sending traffic to isp-01 only to have it forwarded back to isp-02.
Outbound Route Filtering (ORF)
So far, we have applied inbound filtering on our side to make sure we only accept the default route and the ISP’s own prefixes. But there’s still a drawback - both ISPs are still sending us the entire Internet routing table. Even though we filter most of it, our routers still need to process all those updates, which wastes CPU and memory resources.
isp-01#show ip bgp neighbors 185.16.10.3 advertised-routes
BGP table version is 13, local router ID is 10.0.0.5
Network Next Hop Metric LocPrf Weight Path
*> 8.0.0.0 185.16.10.6 0 0 1000 i
*> 95.15.0.0/16 185.16.10.5 0 0 300 i
*> 185.15.0.0 0.0.0.0 0 32768 i
*> 195.15.0.0/16 185.16.10.6 0 1000 400 i
Total number of prefixes 4isp-02#show ip bgp neighbors 95.16.10.3 advertised-routes
BGP table version is 21, local router ID is 10.0.0.6
Network Next Hop Metric LocPrf Weight Path
*> 8.0.0.0 185.16.10.4 0 200 1000 i
*> 95.15.0.0/16 0.0.0.0 0 32768 i
*> 100.10.10.0/24 185.16.10.4 0 200 100 i
*> 185.15.0.0 185.16.10.4 0 0 200 i
*> 195.15.0.0/16 95.16.10.5 0 0 400 i
Total number of prefixes 5This is where Outbound Route Filtering (ORF) comes in. ORF allows us to tell the ISP what routes we actually want from them. Instead of sending us the full table and letting us filter, we can push a filter to the ISP router so that it only sends the routes we need, such as the default route and their own originating prefixes.
clear ip bgp x.x.x.x!! r1 !!
ip prefix-list ORF_LIST seq 5 permit 0.0.0.0/0
ip prefix-list ORF_LIST seq 10 permit 185.15.0.0/16
router bgp 100
address-family ipv4
neighbor 185.16.10.2 capability orf prefix-list send
neighbor 185.16.10.2 prefix-list ORF_LIST in
neighbor 185.16.10.2 route-map INBOUND_MAP in << ALREADY_CONFIGURED!! r2 !!
ip prefix-list ORF_LIST seq 5 permit 0.0.0.0/0
ip prefix-list ORF_LIST seq 10 permit 185.15.0.0/16
router bgp 100
address-family ipv4
neighbor 95.16.10.2 capability orf prefix-list send
neighbor 95.16.10.2 prefix-list ORF_LIST in
neighbor 95.16.10.2 route-map INBOUND_MAP in << ALREADY_CONFIGURED!! isp-01 !!
router bgp 200
address-family ipv4
neighbor 185.16.10.3 capability orf prefix-list receive!! isp-02 !!
router bgp 300
address-family ipv4
neighbor 95.16.10.3 capability orf prefix-list receiveNow, if we check from the ISP routers, we can see that they have received the prefix lists from our routers. As a result, they are only sending us their own prefixes along with the default route, which is shown as Originating default network 0.0.0.0 This confirms that ORF is working as expected.
isp-01#show ip bgp neighbors 185.16.10.3 received prefix-filter
Address family: IPv4 Unicast
ip prefix-list 185.16.10.3: 2 entries
seq 5 permit 0.0.0.0/0
seq 10 permit 185.15.0.0/16isp-01#show ip bgp neighbors 185.16.10.3 advertised-routes
BGP table version is 19, local router ID is 10.0.0.5
Originating default network 0.0.0.0
Network Next Hop Metric LocPrf Weight Path
*> 185.15.0.0 0.0.0.0 0 32768 i
Total number of prefixes 1

