

Welcome back to the third part of our BGP course. In this part, we will look at how to advertise prefixes between BGP peers. As we've touched on earlier, simply setting up BGP neighbours isn't enough to start exchanging route information. You need to tell BGP exactly what you want to share using the network x.x.x.x mask x.x.x.x command. There are a few things you need to take into account for this to work properly, so let's dive in.
As always, if you find this post helpful, press the ‘clap’ button. It means a lot to me and helps me know you enjoy this type of content. If I get enough claps for this series, I’ll make sure to write more on this specific topic.
Overview
Our goal in this section is to configure BGP neighbours across three different Autonomous Systems (AS 1000, AS 100, and AS 2000) to ensure the prefix 100.100.0.0/16, originating from the HQ-01 router, is successfully advertised and propagated.
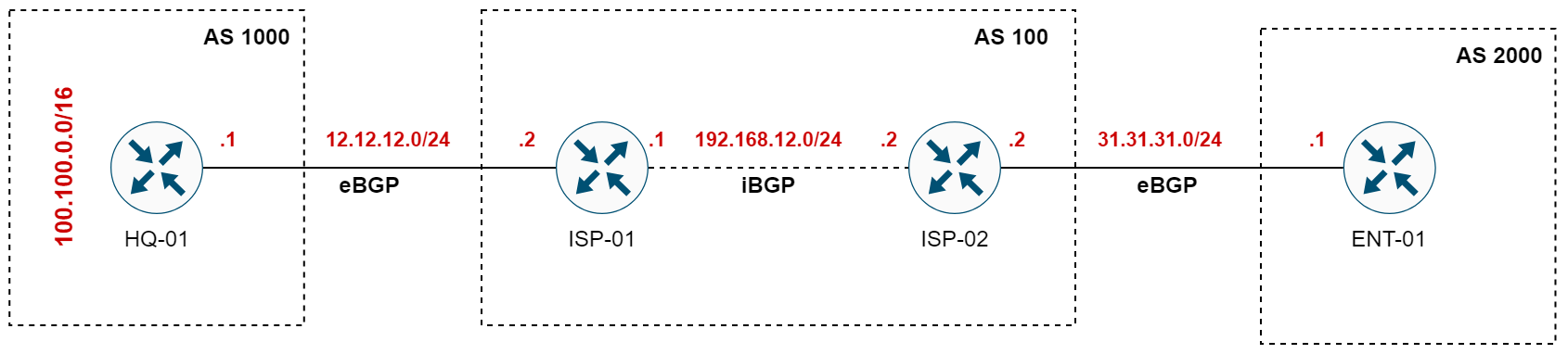
We're working with a network where HQ-01 is in AS 1000, ENT-01 is in AS 2000, and there are two intermediary ISP routers in AS 100. These ISP routers will establish an iBGP session between each other to pass along BGP routes.
We'll set up the BGP configurations on these routers, ensuring that our prefix 100.100.0.0/16 is not only advertised by HQ-01 but also makes it all the way through the ISP routers and reaches ENT-01 in AS 2000. Let’s start by configuring the BGP neighbours and then proceed to monitor the prefix advertisement.
#HQ-01
router bgp 1000
neighbor 12.12.12.2 remote-as 100#ISP-01
router bgp 100
neighbor 12.12.12.1 remote-as 1000
neighbor 192.168.12.2 remote-as 100#ISP-02
router bgp 100
neighbor 31.31.31.1 remote-as 2000
neighbor 192.168.12.1 remote-as 100#ENT-01
router bgp 2000
neighbor 31.31.31.2 remote-as 100Now that we've gone through configuring BGP, the neighborships between the routers should be up and running. However, there's an important step remaining, advertising the prefixes. Here is the output from ISP-01 where you can see the neighbours are up but no prefixes received from HQ-01 (PfxRCd - 0)
#ISP-01
#show ip bgp summary
BGP router identifier 12.12.12.2, local AS number 100
BGP table version is 3, main routing table version 3
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
12.12.12.1 4 1000 1488 1488 3 0 0 22:30:04 0
192.168.12.2 4 100 1487 1486 3 0 0 22:27:32 0BGP network command
Despite successful BGP neighbour establishment, HQ-01 won’t advertise any routes until we explicitly instruct it to. This is where the network x.x.x.x command comes into play. By using this command, we can specify which routes we want HQ-01 to advertise to its BGP neighbours.
When we use the network command in BGP to advertise a specific prefix, BGP has a strict condition it must follow before it can act. For example, if we add network 100.100.0.0 mask 255.255.0.0, BGP will first look at the routing table to verify that an exact match for that prefix exists. Only if there is an exact route match will BGP include that prefix in its own BGP table.
Subsequently, once the prefix is in the BGP table, BGP will advertise this prefix to its neighbours. If, however, the routing table does not contain an exact match for the specific prefix, BGP will not announce that prefix to its peers. Let’s add this command now to start advertising the 100.100.0.0/16 prefix and observe the effects this has on our network.
hq-01(config)#router bgp 1000
hq-01(config-router)#network 100.100.0.0 mask 255.255.0.0Now, if I go and check on ISP-01 again, the prefix received from 12.12.12.1 (HQ-01) should be 1
ISP-01#show ip bgp summary
BGP router identifier 12.12.12.2, local AS number 100
BGP table version is 4, main routing table version 4
1 network entries using 248 bytes of memory
1 path entries using 120 bytes of memory
1/1 BGP path/bestpath attribute entries using 256 bytes of memory
1 BGP AS-PATH entries using 24 bytes of memory
0 BGP route-map cache entries using 0 bytes of memory
0 BGP filter-list cache entries using 0 bytes of memory
BGP using 648 total bytes of memory
BGP activity 2/1 prefixes, 2/1 paths, scan interval 60 secs
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
12.12.12.1 4 1000 1492 1491 4 0 0 22:32:55 1
192.168.12.2 4 100 1490 1490 4 0 0 22:30:22 0ISP-01#show ip bgp
BGP table version is 4, local router ID is 12.12.12.2
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 100.100.0.0/16 12.12.12.1 0 0 1000 iISP-01#show ip route bgp
Gateway of last resort is not set
100.0.0.0/16 is subnetted, 1 subnets
B 100.100.0.0 [20/0] via 12.12.12.1, 00:02:59Everything might look fine from ISP-01's perspective, with a valid (*) and best route (>) to 100.100.0.0/16. You might think we're all set and ready to move on. But let's not rush; it's important to check the other routers as well, specifically ISP-02 and ENT-01.
#ISP-02
ISP-02#show ip bgp
BGP table version is 3, local router ID is 192.168.12.2
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
* i 100.100.0.0/16 12.12.12.1 0 100 0 1000 iENT-011#show ip bgp
ENT-01#On ISP-02, while we see that there's a valid route to 100.100.0.0/16, indicated by an asterisk (*), the route isn’t marked as best (since there's no greater-than sign (>). This means ISP-02 hasn't selected it as the best path, so it won't place this route into its routing table, nor will it advertise the route to ENT-01.
So, we need to dig a little deeper and figure out why ISP-02 doesn't recognize the route as the best and address the issue to ensure the prefix is fully propagated through the network.
BGP Next-Hop Behaviour & Reachability
In BGP, the "next-hop" refers to the next destination that packets will be sent to reach a certain network. For BGP to use and advertise a route, the next-hop IP address for that route must be reachable.
Next-hop is a well-known mandatory path attribute. It is recognized by all BGP peers, passed to all peers, and present in all Update messages. (We will cover Path Attributes in detail in the upcoming sections)
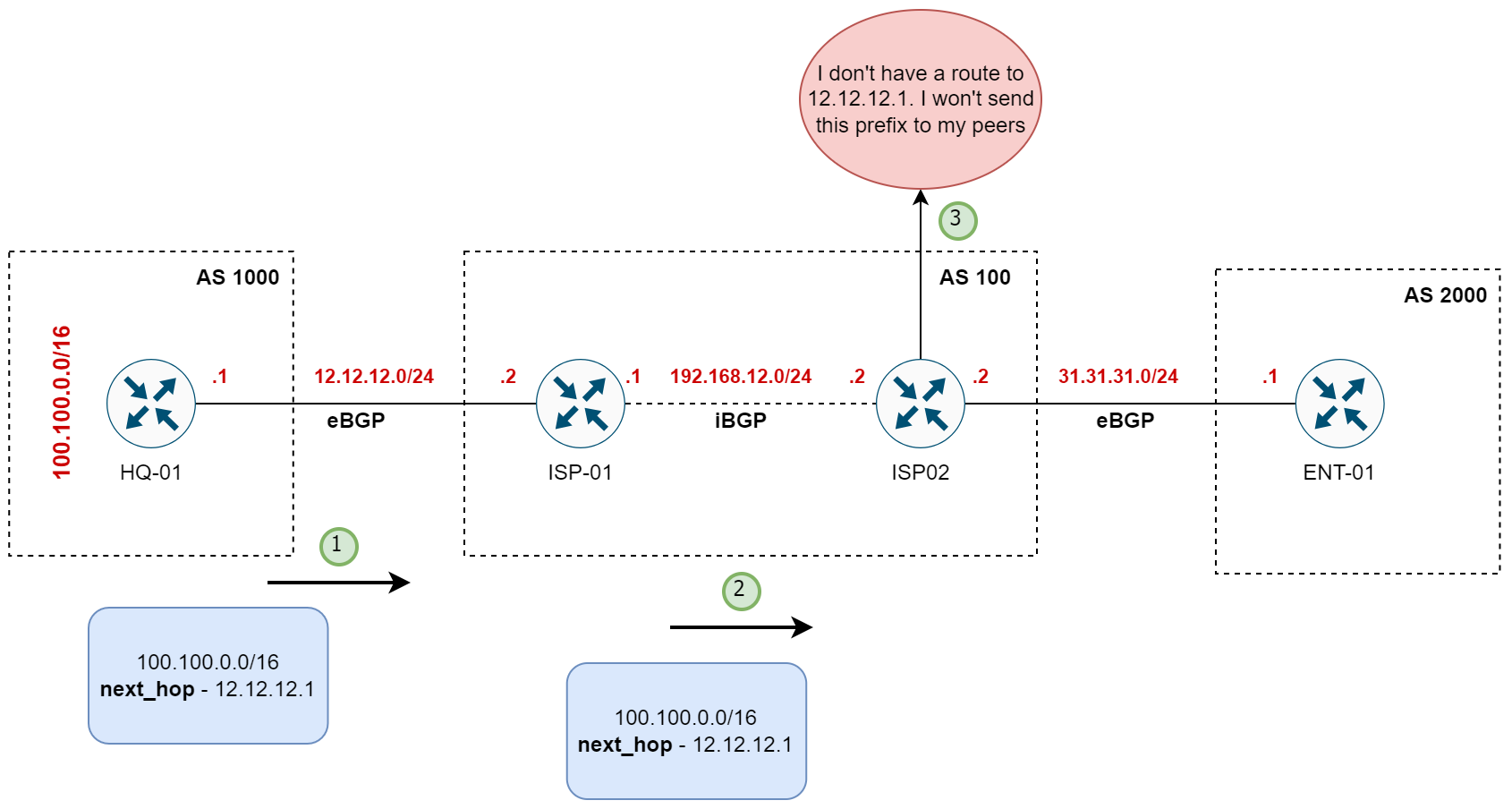
In our example, ISP-01 has learned the route to 100.100.0.0/16 and sees the next hop to reach this network as the IP address of HQ-01 (12.12.12.1). ISP-01 can reach this next hop, so it considers the route valid and best and marks it accordingly.
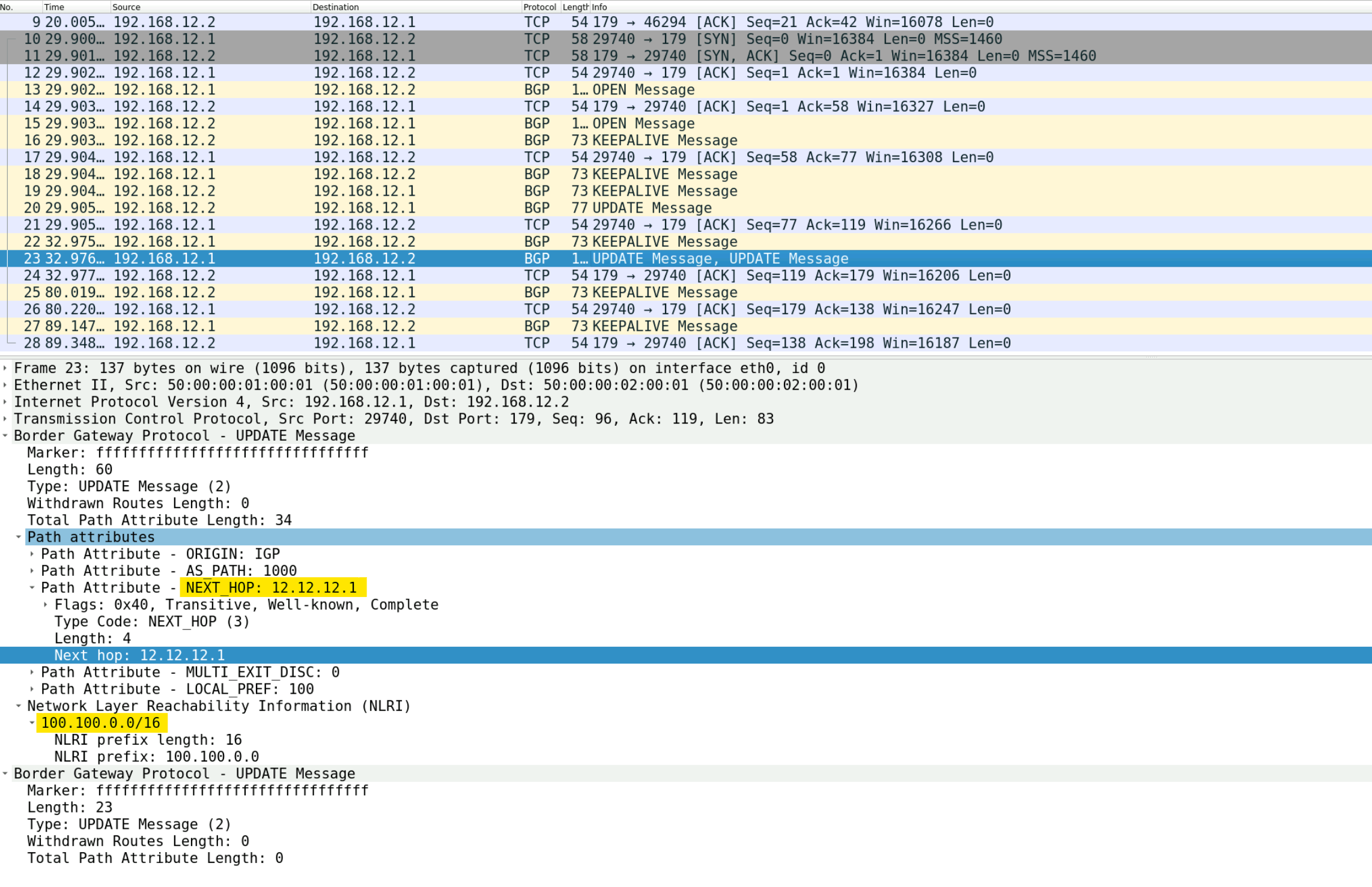
However, ISP-02, which is in the same AS as ISP-01, has learned about the 100.100.0.0/16 network from ISP-01 via iBGP. The catch in iBGP is that the next hop isn't changed when routes are passed along. So, ISP-02 still sees the next hop as the IP address of HQ-01 (12.12.12.1). Here is a capture taken between ISP-01 and ISP-02 and you can see the next-hop IP of 12.12.12.1
If ISP-02 can't reach this next-hop IP, it won't consider the route valid, won't install it in its routing table, and therefore, won't advertise it to ENT-01. Here is a route table of ISP-02 where it doesn't have a route to 12.12.12.x.
#ISP-02
Gateway of last resort is not set
10.0.0.0/8 is variably subnetted, 2 subnets, 2 masks
C 10.10.0.0/16 is directly connected, GigabitEthernet8
L 10.10.50.42/32 is directly connected, GigabitEthernet8
31.0.0.0/8 is variably subnetted, 2 subnets, 2 masks
C 31.31.31.0/24 is directly connected, GigabitEthernet1
L 31.31.31.2/32 is directly connected, GigabitEthernet1
192.168.12.0/24 is variably subnetted, 2 subnets, 2 masks
C 192.168.12.0/24 is directly connected, GigabitEthernet2
L 192.168.12.2/32 is directly connected, GigabitEthernet2Solution 1 - Using an IGP (OSPF)
To solve this, we typically ensure that all iBGP routers within the same AS can reach each other's next-hop addresses, usually by using an IGP like OSPF or by setting up static routes. This ensures that all the necessary next-hop addresses are reachable, allowing routes to be properly installed and advertised. In our scenario, ISP-02 needs to have a reachable route to the next-hop IP address used by HQ-01 to advertise 100.100.0.0/16 in order for it to further advertise this route to ENT-01.
Let's quickly configure OSPF on both ISP routers and see what happens.
#ISP-01
router ospf 1
passive-interface GigabitEthernet1
interface GigabitEthernet1
description hq-01
ip address 12.12.12.2 255.255.255.0
ip ospf network point-to-point
ip ospf 1 area 0
!
interface GigabitEthernet2
description csr-02
ip address 192.168.12.1 255.255.255.0
ip ospf network point-to-point
ip ospf 1 area 0#ISP-02
router ospf 1
passive-interface GigabitEthernet1
interface GigabitEthernet1
description isp-02
ip address 31.31.31.2 255.255.255.0
ip ospf network point-to-point
ip ospf 1 area 0
!
interface GigabitEthernet2
description csr-01
ip address 192.168.12.2 255.255.255.0
ip ospf network point-to-point
ip ospf 1 area 0Now the route for 12.12.12.x shows up on the ISP-02 router's routing table via OSPF. The BGP also shows a valid and best route for 100.100.0.0/16 (denoted by *>)
#ISP-02
Gateway of last resort is not set
12.0.0.0/24 is subnetted, 1 subnets
O 12.12.12.0 [110/2] via 192.168.12.1, 00:00:20, GigabitEthernet2#ISP-02
BGP table version is 4, local router ID is 192.168.12.2
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*>i 100.100.0.0/16 12.12.12.1 0 100 0 1000 iNow the route should propagate all the way to ENT-01 as shown below.
#ENT-01
ENT-01#show ip bgp
BGP table version is 4, local router ID is 31.31.31.1
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 100.100.0.0/16 31.31.31.2 0 100 1000 i
ENT-021#show ip route bgp
Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP
Gateway of last resort is not set
100.0.0.0/16 is subnetted, 1 subnets
B 100.100.0.0 [20/0] via 31.31.31.2, 00:04:01Suppose ENT-01 sends some traffic destined for 100.100.x.x, here is what will happen.
- ENT-01 sends the traffic to ISP-02
- ISP-02 will look at its BGP table to find out the next-hop IP for the prefix 100.100.0.0/16, which is 12.12.12.1
- Next, ISP-02 will check its own routing table to determine the best IGP route to reach this next-hop IP of 12.12.12.1. This includes choosing the right egress interface and the next-hop IP to use. In this case, the next-hop IP to reach 12.12.12.1 is 192.168.12.1
- ISP-02 will send the packets to ISP-01
- ISP-01 receives the traffic, looks at its own routing table and forwards the traffic to HQ-01
Solution 2 - BGP next-hop-self
Another way to address the next-hop reachability issue in iBGP is to use the next-hop-self command. This command changes the next-hop address of a BGP route to the IP address of the router that's sending the route when passing it to iBGP peers.
Here's how it applies to our example. ISP-01 receives the prefix 100.100.0.0/16 from HQ-01 with HQ-01's IP as the next hop. When ISP-01 sends this route to ISP-02, it can use next-hop-self to change the next hop from HQ-01's IP to its own IP. This way, ISP-02 will see the next hop as ISP-01, which it can reach because they're directly connected within the same AS. Now, ISP-02 will consider the route valid, install it in its routing table, and then advertise it to ENT-01. Using next-hop-self is a common solution in iBGP configurations to ensure all peers have reachable next-hop addresses.
#ISP-01
router bgp 100
neighbor 12.12.12.1 remote-as 1000
neighbor 192.168.12.2 remote-as 100
neighbor 192.168.12.2 next-hop-self <<<< Here is the changeAs soon as I do this and take the captures from the same interface, you will see a difference. Now the next-hop IP is set to 192.168.12.1 which is directly connected to ISP-02.
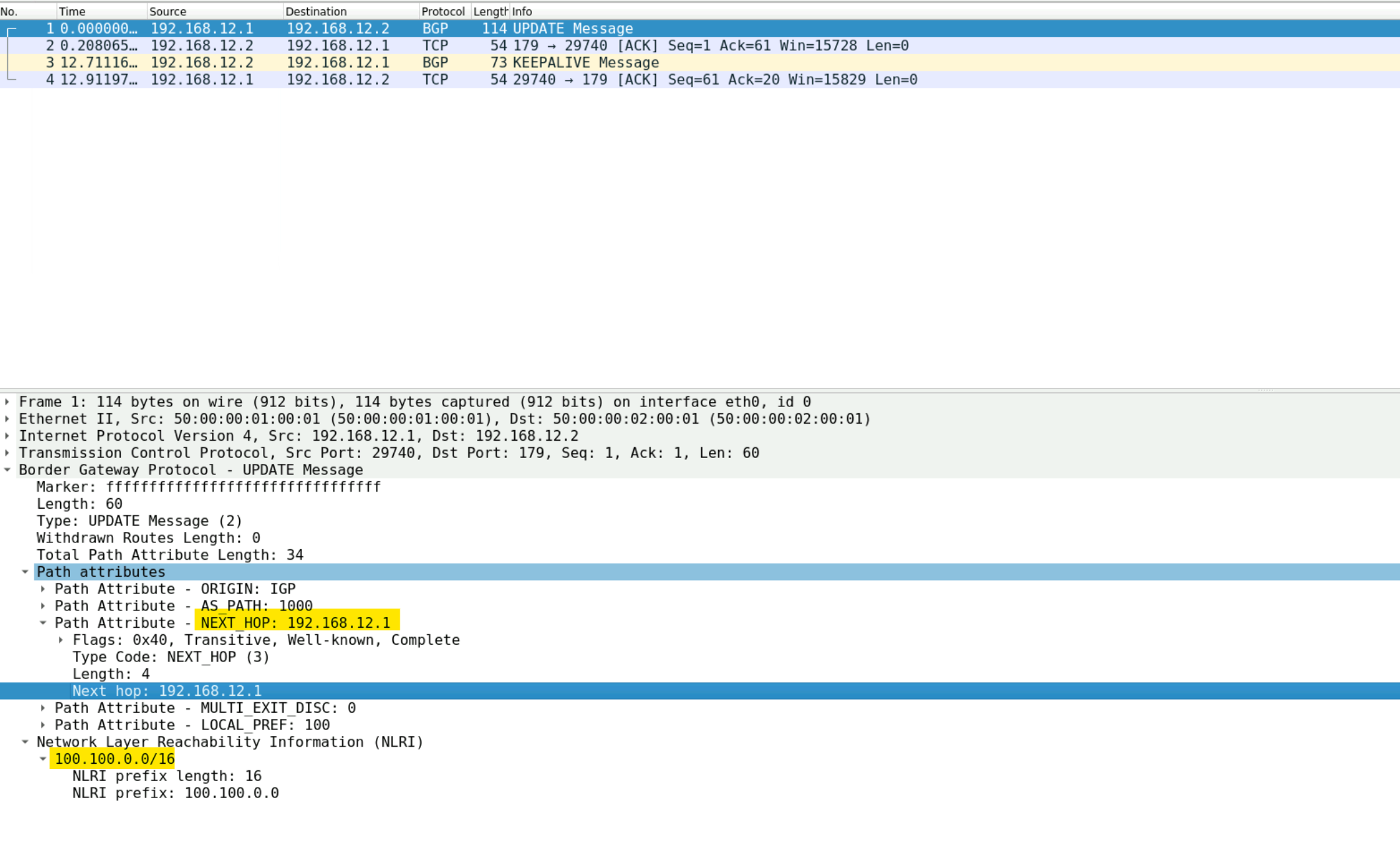
If we go back to ENT-01, we should see the prefix and everything looks good.
#ENT-01
ENT-01#show ip bgp
BGP table version is 6, local router ID is 31.31.31.1
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 100.100.0.0/16 31.31.31.2 0 100 1000 iThe key takeaway here is, if the next-hop is unreachable for a specific prefix, the BGP router will not advertise the prefix to its neighbours and will not also instal the prefix in ints own routing table.
BGP Only Advertises the Best Route
It's crucial to remember that BGP advertises only the best route to its neighbours. What this means is that for each destination, BGP picks the best route based on its path selection algorithm, and that's the only route it advertises.
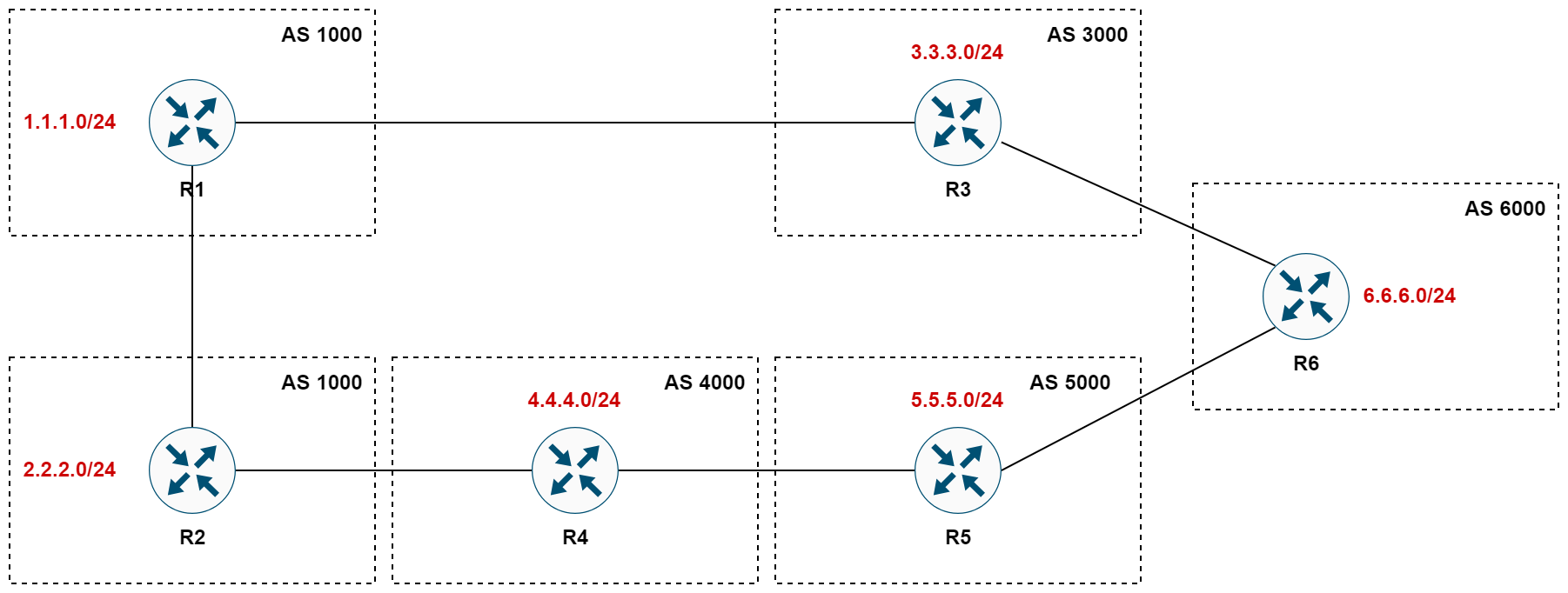
Take the network 3.3.3.0/24 in the diagram, for example. This network originates from R3 and can reach R5 through multiple paths. One path is through R6 directly, and another is a longer path through R1, R2, and then R4. Despite knowing multiple paths, from R5's point of view, the best route to reach 3.3.3.0/24 is the one through R6, which is directly connected to R3.
Consequently, R5 will not propagate the route that it learned via the longer path to R6 or to any other neighbours it might have. R5 will only advertise the route it considers best which, in this scenario, is the path through R6 to R3 to its neighbors.
BGP Redistribution
You can also redistribute routes from other routing protocols into BGP using the redistribute command. For example, instead of using the network command to inject prefixes into BGP, I could also redistribute the connected routes.
#HQ-01
hq-01(config-router)#no network 100.100.0.0 mask 255.255.0.0
hq-01(config-router)#redistribute connected
hq-01(config-router)#endIf I go to ISP-01 and check the routes, I should be able to see the prefix 100.100.0.0/16 as shown below.
#ISP-01
isp-01#show ip bgp
BGP table version is 6, local router ID is 192.168.12.1
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
r> 10.10.0.0/16 12.12.12.1 0 0 1000 ?
r> 12.12.12.0/24 12.12.12.1 0 0 1000 ?
*> 100.100.0.0/16 12.12.12.1 0 0 1000 ?If you are wondering why are we seeing not only 100.100.0.0/16 but also the other two subnets 10.10.0.0/16, and 12.12.12.0/24, well they are directly connected to the HQ-01 router. (Please ignore 10.10.0.0/16 as I'm just using that as a management subnet)
BGP Routing Information Base
The entire set of BGP routes that a router learns and advertises makes up its BGP Routing Information Base (RIB). Conceptually, the BGP RIB is divided into three parts.
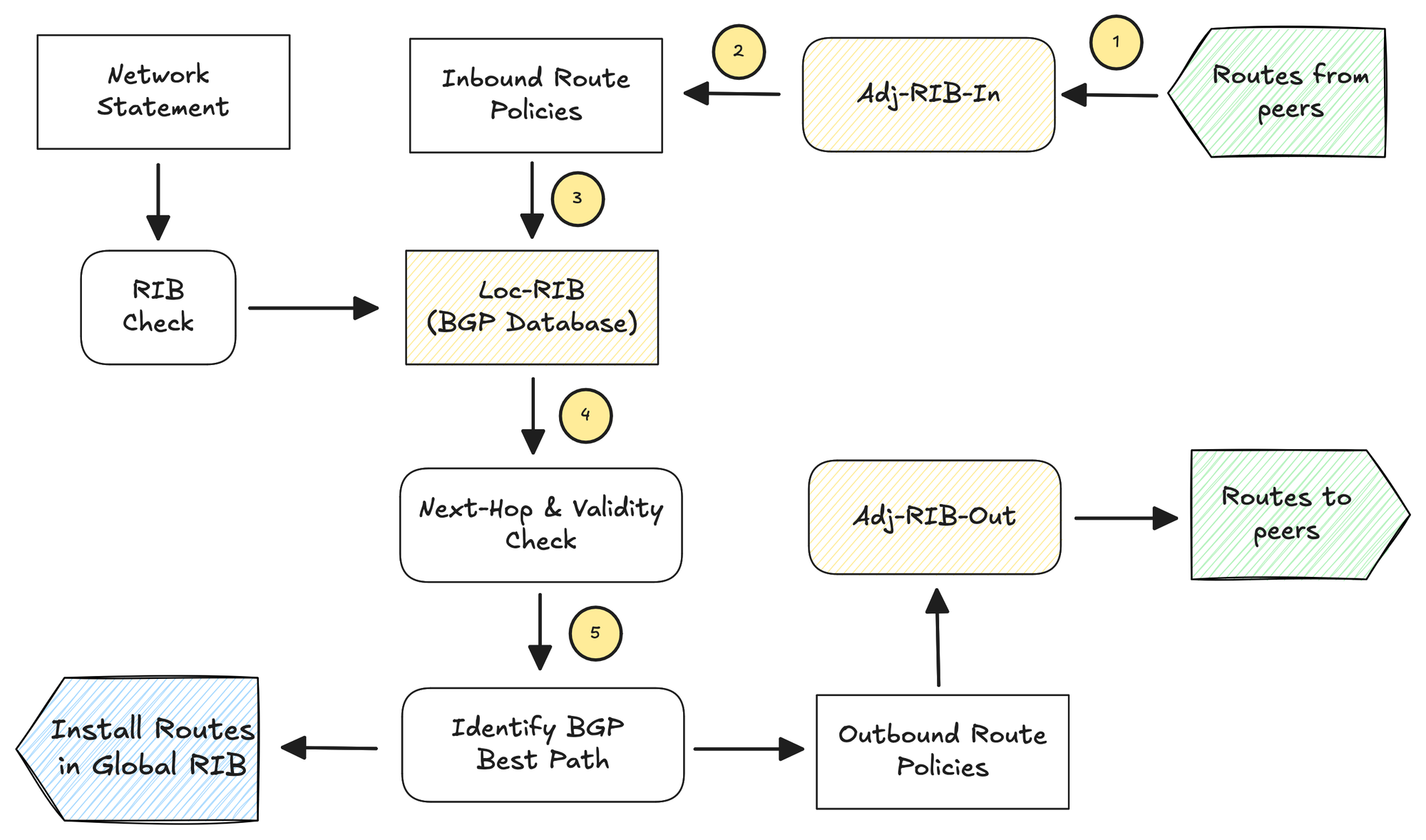
- RIB-IN - The RIB-IN (or Adj-RIBs-In as defined in RFC 4271) holds the routes received from peers that the router decides to keep in memory. Before they are accepted into the local database, inbound route policies can be applied to filter or modify these routes.
- LOC-RIB - The LOC-RIB is the local BGP database. It contains the modified versions of the routes learned from the RIB-IN. At this stage, BGP performs next-hop and validity checks to make sure the routes are usable. The BGP decision process then compares all available paths for the same prefix and selects the best path. These best paths are installed in the global RIB (the main routing table of the router) and are the ones actually used for forwarding traffic.
- RIB-OUT - The RIB-OUT (or Adj-RIBs-Out as defined in RFC 4271) contains the routes that will be advertised to peers. These routes are taken from the LOC-RIB, passed through outbound route policies, and then sent to neighbours. A single route can even be advertised differently to different peers depending on the outbound policy applied.
This process ensures you can control which routes you accept, which routes you actually use, and which routes you advertise.
BGP RIB Example
Let’s look at the BGP Routing Information Base with a simple example. In this case, R1 and R2 have an eBGP session, and R2 advertises two prefixes, 172.16.0.0/24 and 172.16.1.0/24, to R1. Since no BGP policies are applied, R1 receives these prefixes and installs them in its routing table.
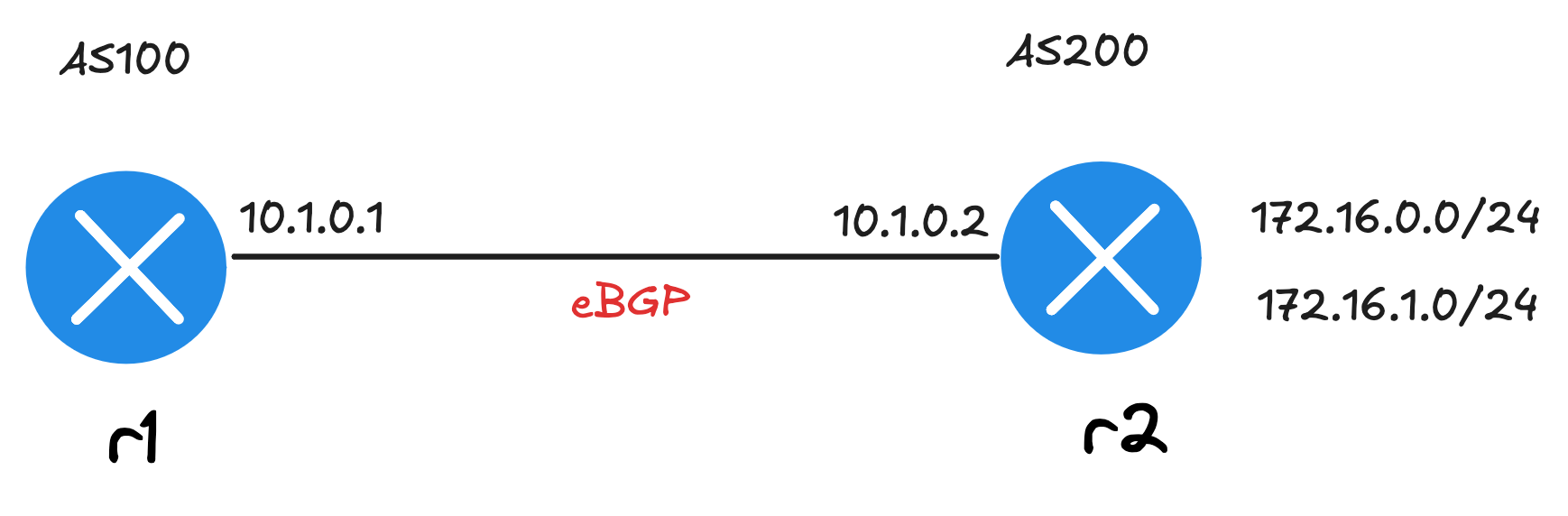
Because we are not modifying attributes or applying any filtering yet (we will cover filtering and attributes later in the series), we don’t really need to worry about what was originally received in the RIB-IN. What matters here is what R1 ends up storing in its LOC-RIB and using for forwarding. To check which prefixes were accepted into the LOC-RIB from R2, we can use the following command.
r1#show ip bgp neighbors 10.1.0.2 routes
BGP table version is 18, local router ID is 10.0.0.1
Network Next Hop Metric LocPrf Weight Path
*> 172.16.0.0/24 10.1.0.2 0 110 0 200 i
*> 172.16.1.0/24 10.1.0.2 0 110 0 200 i
Total number of prefixes 2Now, let’s go and filter the prefixes received from R2. To do this, we first create a prefix-list that allows only 172.16.0.0/24. Then we reference that prefix-list in a route-map. The route-map acts like a container where we can match conditions, in this case the prefix-list, and then take action.
ip prefix-list FROM-R2 seq 10 permit 172.16.0.0/24
route-map RM-R2 permit 10
match ip address prefix-list FROM-R2
router bgp 100
bgp log-neighbor-changes
neighbor 10.1.0.2 remote-as 200
neighbor 10.1.0.2 route-map RM-R2-LP inWhen we apply the route-map inbound to the BGP neighbour, R1 will only accept the 172.16.0.0/24 prefix from R2. Any other prefixes, like 172.16.1.0/24, will be filtered out and not installed in the LOC-RIB. This is the basic way BGP filtering works and gives us control over which routes we allow into our network.
r1#show ip bgp neighbors 10.1.0.2 routes
BGP table version is 19, local router ID is 10.0.0.1
Network Next Hop Metric LocPrf Weight Path
*> 172.16.0.0/24 10.1.0.2 0 110 0 200 i
Total number of prefixes 1 Now, we can see that in the LOC-RIB only 172.16.0.0/24 is present, so everything looks good so far. But let’s say we also want to allow 172.16.1.0/24. If we go back and update the prefix-list to include this second prefix, will it work? Not quite the way you might expect.
BGP does not continuously resend all routes to its neighbours. Instead, it only sends updates when something changes, like a new route being advertised or an existing one being withdrawn. Since R2 has already advertised both prefixes earlier, it is not going to automatically resend them just because we changed the filter on R1.
At this point, you might think it’s fine because the original routes should still be stored in the RIB-IN. That would mean R1 could simply reprocess them with the updated policy. But again, that is not exactly the case. So how do we even check what’s in the RIB-IN? On Cisco devices, we can try the following command.
r1#show ip bgp neighbors 10.1.0.2 received-routes
% Inbound soft reconfiguration not enabled on 10.1.0.2Here, the router is telling us that inbound soft reconfiguration is not enabled for this neighbour. But what does that even mean, you may wonder.
BGP Route Refresh
So, we know that R1 does not keep the originally received prefixes in the RIB-IN since inbound soft reconfiguration is not enabled. But before we dive into what inbound soft reconfiguration is, let’s actually test what happens if we update the prefix-list. I added a new entry to allow 172.16.1.0/24, waited a few seconds, and then checked the LOC-RIB. Now both prefixes show up.
ip prefix-list FROM-R2 seq 20 permit 172.16.1.0/24r1#show ip bgp neighbors 10.1.0.2 routes
BGP table version is 20, local router ID is 10.0.0.1
Network Next Hop Metric LocPrf Weight Path
*> 172.16.0.0/24 10.1.0.2 0 110 0 200 i
*> 172.16.1.0/24 10.1.0.2 0 110 0 200 i
Total number of prefixes 2 This might seem confusing because we clearly do not have inbound soft reconfiguration enabled. The reason it works is because of BGP Route Refresh.
With route refresh, instead of storing all original received routes in memory, R1 can simply request R2 to resend its routing information when policies change. In our debug output, we can see this happening. R1 sends a refresh request, R2 responds, and the routes are resent and reprocessed under the new policy.
debug ip bgp*Aug 31 18:59:30.716: BGP: 10.1.0.2 sending REFRESH_REQ(5) for afi/safi: 1/1, refresh code is 0
*Aug 31 18:59:30.717: BGP: 10.1.0.2 rcv message type 5, length (excl. header) 4
*Aug 31 18:59:30.717: BGP: 10.1.0.2 rcvd REFRESH_REQ for afi/safi: 1/1, refresh code is 1
*Aug 31 18:59:30.721: BGP: 10.1.0.2 rcv message type 5, length (excl. header) 4
*Aug 31 18:59:30.721: BGP: 10.1.0.2 rcvd REFRESH_REQ for afi/safi: 1/1, refresh code is 2If we check the neighbour capabilities, we can confirm that route refresh is supported. You can see under the neighbour capabilities that route refresh is both advertised and received, which means both routers agree to use it.
r1#show ip bgp neighbors 10.1.0.2 | beg capa
1 active, is not multisession capable (disabled)
Neighbor capabilities:
Route refresh: advertised and received(new)
Four-octets ASN Capability: advertised and received
Address family IPv4 Unicast: advertised and receivedThis is why even without inbound soft reconfiguration enabled, R1 was still able to reapply the updated prefix-list and accept the additional route.
In September 2000, RFC 2918 was proposed. This RFC introduced the Route Refresh Capability for BGP, allowing the BGP speaker to send a Route Refresh Message to the peer requesting the resend of all prefixes whenever an inbound policy is applied or modified. This completely removes the necessity of having to store a duplicate copy of the peer’s prefixes, saving CPU and memory resources.
Inbound Soft Reconfiguration
Inbound soft reconfiguration is a feature that allows the router to keep an unmodified copy of all prefixes it receives from a peer. This means the router stores the original routes in memory before any inbound policy is applied. Once it is enabled, you can always look back at what was received, regardless of how the policies are currently filtering or modifying those routes.
router bgp 100
bgp log-neighbor-changes
neighbor 10.1.0.2 remote-as 200
neighbor 10.1.0.2 soft-reconfiguration inbound
neighbor 10.1.0.2 route-map RM-R2-LP inAfter configuring inbound soft reconfiguration on R1, we can now use the show ip bgp neighbors 10.1.0.2 received-routes command to see the prefixes exactly as they were received from R2.
r1#show ip bgp neighbors 10.1.0.2 received-routes
BGP table version is 23, local router ID is 10.0.0.1
Network Next Hop Metric LocPrf Weight Path
* 172.16.0.0/24 10.1.0.2 0 0 200 i
* 172.16.1.0/24 10.1.0.2 0 0 200 i
Total number of prefixes 2 Now we can clearly see both prefixes that were originally sent by R2, even if our route-map later filters one of them out. The trade-off, however, is that enabling inbound soft reconfiguration requires extra memory on the router since it has to keep a copy of all received routes.


